3D-Grounded Visual Editing and Generative Compositing
A 3D-grounded
visual compositing framework, providing precise control and composition of various visual elements, including objects, camera, and background.
BlenderFusion employs a layering-editing-compositing process:
Object-centric Layering: Segment and lift object from source images into editable 3D elememnts, leveraging visual foundation models.
Blender-grounded Editing: Edit and manipulatethe various visual elements in Blender, render the initial and target scenes to provide strong 3D grounding.
Generative Compositing: Adapt a diffusion model into a generative compositor, compose everything into the target image.
1Google DeepMind2Simon Fraser University3New York University
*Work done during internship at Google†Corresponding authors
TL;DR: BlenderFusion combines the accurate 3D geometric control of Blender with a generative compositor (adapted from pre-trained Stable Diffusion v2) to enable precise geometry editing and versatile visual compositing, which are hard to achieve through the text control protocol.
Visual compositing, a key component of visual effects (VFX), refers to the process of assembling multiple visual elements into a single, coherent image. It typically involves the following steps:
Layering: Segment objects from the background, estimate camera parameters, and reconstruct a 3D scene layout.
Editing: Modify object properties, reposition elements, adjust camera views, and update scene context.
Compositing: Integrate all modified elements seamlessly, ensuring consistency in lighting, perspective, and appearance to produce the final image.
Despite tremendous progress in image generation and editing, precise visual compositing remains challenging for state-of-the-art models with text interface. Look at the following example with GPT-4o image generation, results are obtained on June 9th, 2025 through the ChatGPT App.
Challenges in text-based visual compositing: While advanced text-to-image models excel at semantic-level control, they struggle with geometric-level instructions for precise spatial relationships, object poses, and camera viewpoints—demonstrating the inadequacy of text interfaces for complex visual compositing tasks.
While state-of-the-art text-to-image models excel at semantic-level control and can iteratively correct object appearance or shape, they struggle with geometric-level instructions due to limited 3D understanding.
Moreover, text interfaces are inherently inadequate for precise geometric control and complex compositing—describing spatial relationships, object geometries or poses, and camera viewpoints through text prompts is often tedious, ambiguous, and imprecise.
BlenderFusion addresses these limitation by combining the best of both worlds: we decompose visual compositing into 3D-grounded editing and generative synthesis.
Instead of relying solely on text prompts, we leverage graphics engines (Blender) for precise geometric control and flexible manipulation, then employ diffusion models as a generative compositor to synthesize the final photorealistic result.
This approach provides flexible and fine-grained control over objects, camera, and background, while harnessing the powerful synthesis capabilities of modern generative models.
In the following section, we detail our three steps that mirrors the layering-editing-compositing process of traditional visual compositing.
Method Overview
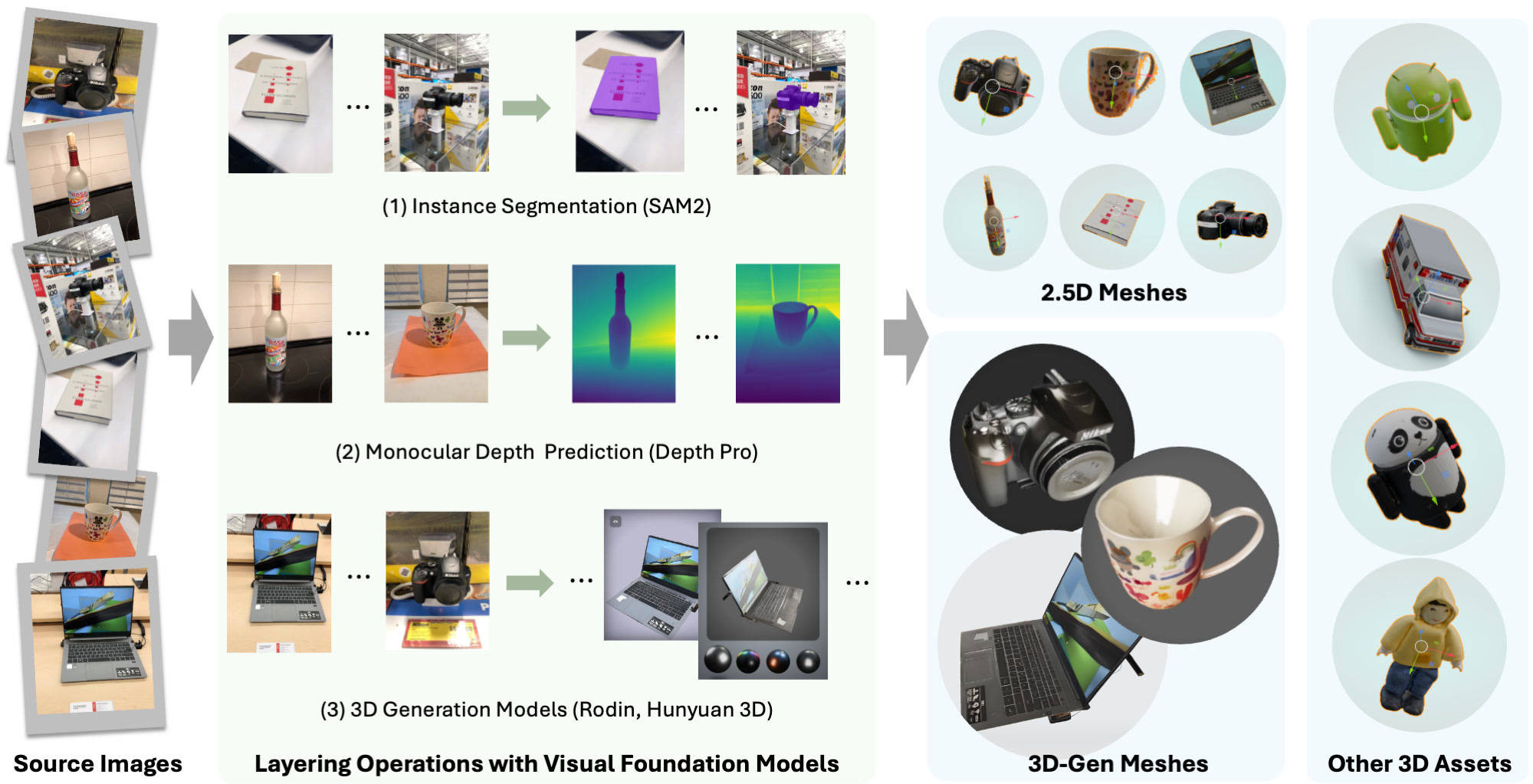
Step 1: Object-centric Layering
The first step, object-centric layering, aims to extract objects of interest from one or more source images and lift them into editable 3D elements.
We leverage several visual foundation models in this process:
A segmentation model (SAM2) to produce accurate object masks, using object box as the prompt;
A monocular depth estimation model (Depth Pro) to estimate the depth, which allows us to back-project the object using the mask and depth information to obtain a 2.5D surface mesh, serving as the 3D proxy of the object. The processing is fast and used to prepare the training data in large scale;
(Optional) An image-to-3D model (Rodin , Hunyuan3D ) to generate complete 3D meshes and align their poses to the 2.5D mesh, enabling more flexible editing at test time.
Step 1: Object-centric Layering: Obtain editable objects from source images or other existing 3D assets.
Step 2: Blender-grounded Editing
The editable objects from the previous step are then imported into Blender, where diverse programmic and manual editings can be applied. We cover both object and camera controls. The object control includes basic object rigid transformations and more advaned controls (color, texture, part-level editing, novel objects, etc.).
The camera control includes camera viewpoint and background change, where the background replacement is directly handled in the generative compositing step.
Step 2: Blender-grounded Editing: Versatile object and camera controls through a graphics engine (Blender). The accurate controls are difficult to achieve with implicit control protocols (text or 3D bounding boxes).
The render results provide reliable 3D grounding for the generative compositing step.
When rendering the original and edited scenes to obtain 3D grounding for the generative compositing step, we disable all shading effects and use only the emission shader, allowing the diffusion-based compositor to handle lighting and shading. Note that the 2.5D mesh is inherently rough and can become incomplete when the viewpoint changes or objects are transformed, requiring the generative compositor to perform shape understanding and completion.
Nevertheless, our generative compositor benefits from much more reliable 3D grounding provided by the graphics software, in contrast to text-to-image models that must handle complex editing and compositing tasks based on vague or ambiguous text descriptions and other implicit encodings.
Step 3: Generative Compositing
In the generative compositing step, we employ a diffusion model as a generative compositor to blend and synthesize the final photorealistic image. The compositor is adapted from a pre-trained Stable Diffusion v2.1 model with several key architectural modifications:
The dual-stream architecture processes information from both the original scene (before editing) and the target scene (after editing) in parallel;
The source stream takes the background image (with original foreground masked out if necessary for background replacement) and the initial Blender render from the imported 3D objects. The target stream takes the noisy target image, the target Blender render (after object and camera manipulations), and the relative camera pose (in Plücker encoding) as geometric control signals;
The cross-view attention mechanism extends the original self-attention layers of the denoising network to operate on both streams simultaneously, allowing proper blending of source and target information;
The 3D object bounding boxes provide additional spatial constraints, encoded and injected through the text embedding interface.
Step 3: Generative Compositing: Our generative compositor is adapted from Stable Diffusion v2.1. The network processes the source stream (original scene) and the target stream (target scene) in parallel and uses cross-view self attention to blend the information. Highly fine-grained editing and compositing can be achieved.
The compositor is trained on pairs of video frames with object and camera pose information. We design two tailored training strategies for flexible and disentangled control. Source masking randomly drops the source stream information during training, enabling us to effectively mask out information from the original scene when performing aggressive edits (such as background replacement or object removal).
Simulated object jittering perturbs the objects while keeping the camera fixed, greatly facilitating disentangled object control. Please see the next section below for extensive qualitative results.
Results Demos
We demonstrate BlenderFusion across four key task settings and compare against Neural Assets ,
a state-of-the-art method for 3D-aware multi-object control that disentangles foreground objects and background.
Disentangled object control: Transform objects while keeping the camera fixed
Disentangled camera control: Manipulate camera viewpoint with mostly static objects
Fine-grained compositing: Complex scene editing and recomposition
Out-of-distribution generalization: Editing unseen domains and progressive object-level tasks
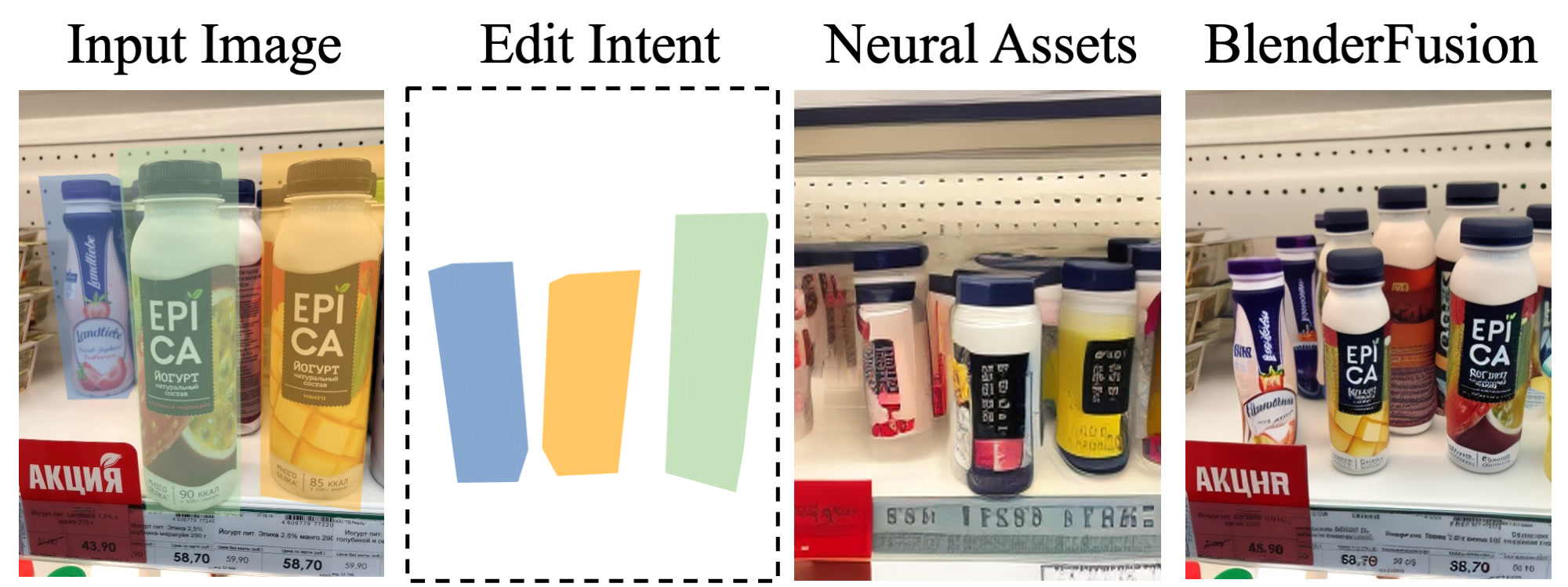
Disentangled Object Control
We demonstrate object translation, rotation, and scaling on Objectron and Waymo Open Dataset.
Results show: source image with colored 3D boxes indicating editing intent, Neural Assets baseline,
Blender render using either 2.5D surface reconstruction or complete 3D meshes from image-to-3D models,
and BlenderFusion final results from our generative compositor.
🎮 Interactive Controls: Click or drag the sliders to transform objects • Click Reset to return to default positions • Click Expand to see more examples
Observation: Our generative compositor is able to correct broken or incomplete shapes from the 2.5D Blender renderings, completing object geometry and synthesizing realistic lighting and shading effects. This demonstrates the power of combining precise 3D geometric control with advanced generative modeling.
We demonstrate camera viewpoint manipulation from a single source image.
Results show: source image, Neural Assets baseline, BlenderFusion output, and ground truth target from video frames.
(1) Objectron Results
While background regions not visible in the source image may vary across viewpoints due to independent per-view generation,
BlenderFusion still achieves significantly better overall view consistency compared to the baseline, particularly for visible objects and spatial relationships.
Future work could further enhance multi-view consistency through video-based generation or explicit multi-view conditioning.
Objects present in the source image maintain appearance consistency across different camera viewpoints.
Objects absent from the source (guided by 3D bounding boxes) are synthesized but may vary across views due to independent generation per viewpoint.
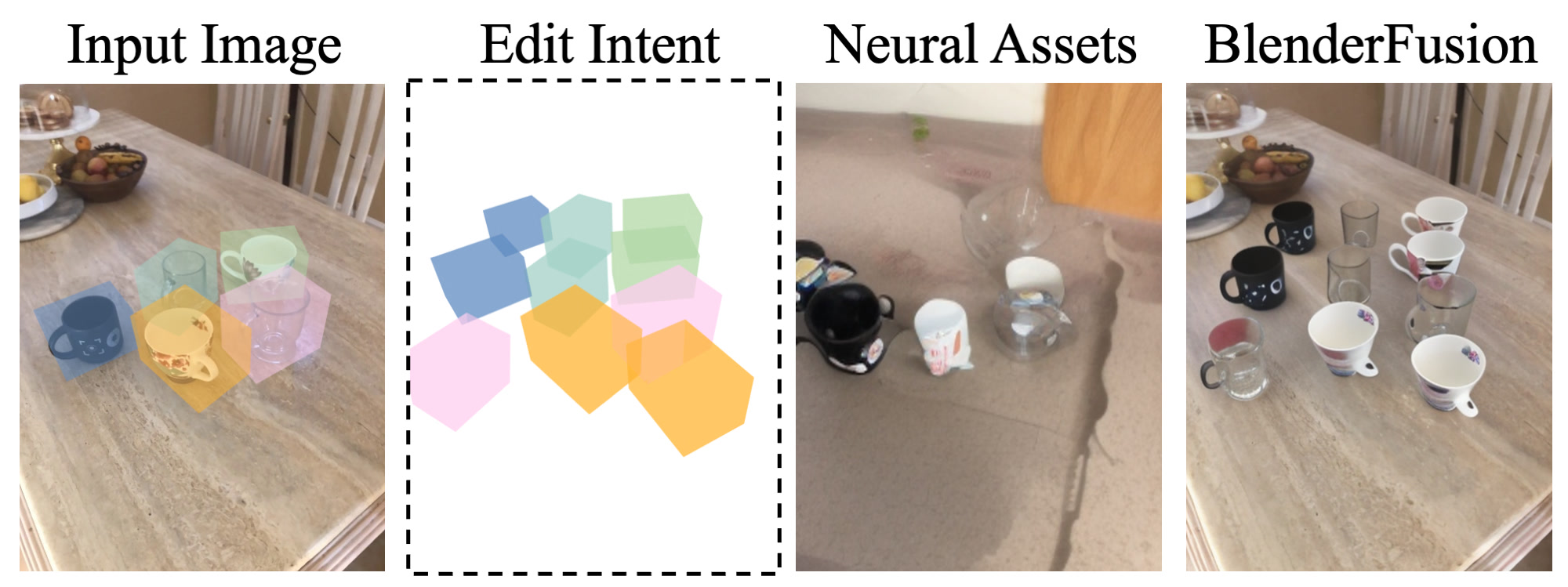
BlenderFusion enables complex visual compositing tasks that go beyond simple object transformations.
We demonstrate sophisticated editing capabilities including more complex multi-object manipulation within single images and
cross-image scene recomposition. These examples showcase the framework's ability to handle intricate spatial
relationships and maintain visual coherence across complex editing scenarios.
(1) Single-image Complex Manipulation
Object Manipulation: Re-arrange and re-scale four shoes Object Manipulation: Re-arrange and re-scale three bottles Object Manipulation: Re-arrange and re-scale three bottles Object Manipulation: Re-arrange and re-scale three chairs Object Duplication: Duplicate and re-arange four cupsObject Duplication: Duplicate and re-arange five cups
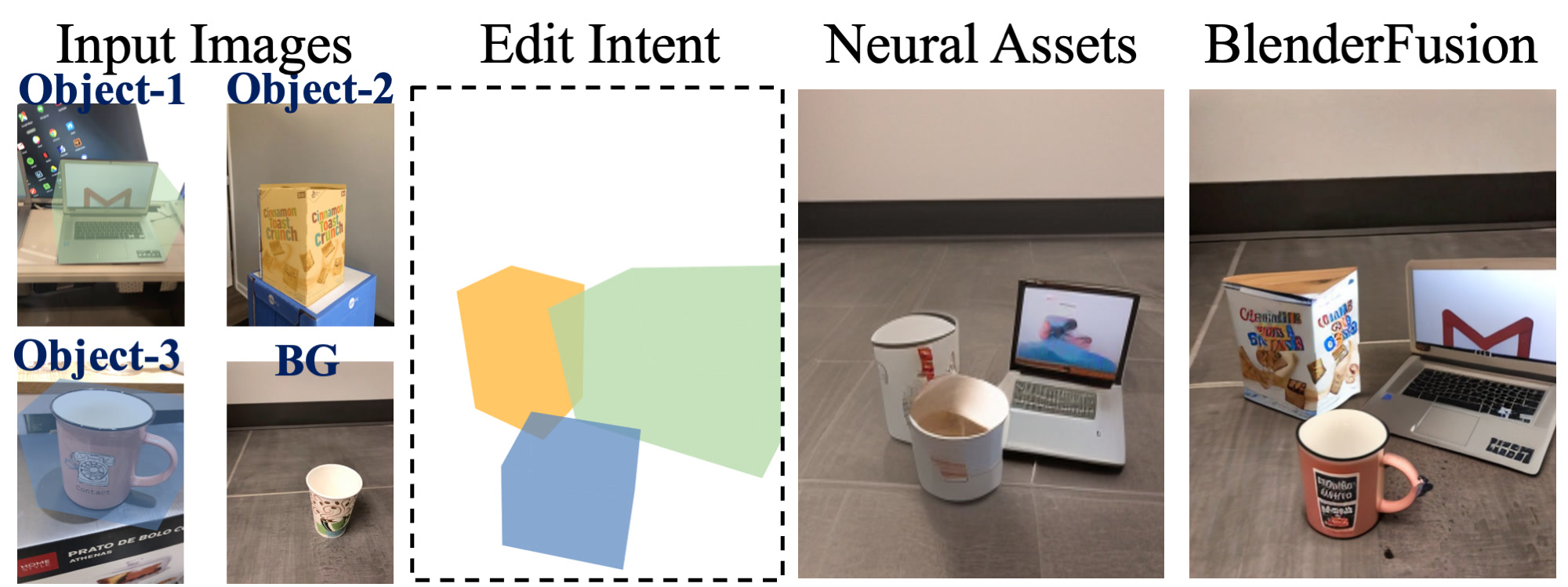
(2) Multi-image Scene Recomposition
Scene Recompositing: Two objects and background from three images Scene Recompositing: Three objects and background from four images
Scene Recompositing: Objects from image 1, 2, 3; Background from image 2; Layout specified by image 4 Scene Recompositing: Objects from image 1, 2; Background from image 3; Layout specified by image 4
Out-of-Distribution Generalization
(1) Editing In-the-Wild Images
BlenderFusion can be applied to in-the-wild images and works reasonably on unseen scenes and objects.
SUN RGB-D and ARKitScenes are real-world indoor scene datasets, while Hypersim is a complicated synthetic indoor scene dataset.
Generalization: Images are from the SUN RGB-D dataset. Generalization: Images are from the ARKitScenes dataset. Generalization: Images are from the Hypersim dataset.
(2) Progressive Object Editing
BlenderFusion inherits Blender's comprehensive object editing capabilities, enabling the generative compositor
to handle advanced editing tasks beyond those covered in training data. The framework supports progressive
multi-step editing workflows including color modification, material changes, part-level manipulation, geometric
deformation, and text engraving. These examples demonstrate the extensibility and versatility of our approach
for complex creative workflows.
Progressive Editing: Color change → Rotation → Text engraving → Shape deformation. Progressive Editing: Color change → Part-level manipulation → Texture change → Rigid transform.
BibTeX
@article{chen2025blenderfusion,
title={BlenderFusion: 3D-Grounded Visual Editing and Generative Compositing},
author={Chen, Jiacheng and Mehran, Ramin and Jia, Xuhui and Xie, Saining and Woo, Sanghyun},
year={2025},
journal={arXiv preprint arXiv:2506.17450}
}
This project page template is adapted from V-IRL and Cambrian-1, thanks for the beautiful template!